
Live stream monitoring is one of the key success factors for OTT streaming providers. It’s what ensures high Quality of Experience (QoE) for viewers in a crowded market where high latency, buffering, and downtime don’t just lead to increased customer churn but can result in ruined relationships with viewers forever. In the ever-more competitive live streaming OTT market, rapid responses to issue prevention are vital to meeting the needs of demanding users, and ensuring the Quality of Service customers expect.
This article looks at the main challenges of live stream monitoring, solutions to overcoming them, a mini case study, and how OTT operators benefit from them.
- Live stream monitoring challenges
- Live stream monitoring solutions
- Live stream monitoring example
- Live stream monitoring benefits
Live stream monitoring challenges
Monitoring OTT streams is much different from monitoring broadcasts over cable. The latter is based on proven processes, tools, and standardisations that have been developed over decades. Unfortunately, the streaming ecosystem doesn’t enjoy such benefits; it’s much more complex and subject to greater change. As such, it poses various challenges.
Connecting the dots effectively amidst data fragmentation
Market research done by Touchstream revealed that overcoming data fragmentation is one of the biggest obstacles for streaming operations teams. The root cause of this industry-wide problem is a combination of a lack of sufficient standardisation and a high pace of innovation. As a result, operations teams struggle to access and unify monitoring data from various constantly evolving sources. This reduces observability, making it impossible to monitor live streams with enough detail and efficiency.
Scaling and growing monitoring operations efficiently
Another byproduct of data fragmentation is that it severely hinders streaming scalability. OTT technology and tools are evolving rapidly, meaning companies have to regularly update existing infrastructure and integrate new tools to ensure monitoring data is connected. This drains time and resources that would be better spent focusing on QoE. In addition to IT maintenance and integration costs, further budget is lost as staff have to be constantly retrained on how to operate the latest technologies.
All of this makes it difficult for streaming companies to grow.
Accelerating root cause analysis and mean time to repair
One of the most commonly mentioned monitoring challenges in our customer research analysis is analysing root causes and resolving them quickly enough. Again, this problem can be largely traced back to fragmentation of data:
“Troubleshooting can take days or even months because data is fragmented across different sources, often without access to data”
- Technical Operations Manager at a major US streaming company
There are three main problems: first, fragmentation makes identifying the root cause of errors difficult and time-consuming, leading to a high Mean Time to Diagnose Issues (MTTDI). Second, this already high MTTDI is further compounded by human misguidance or errors, as there is simply too much data to parse manually. Finally, even once a root cause has been detected, operations teams still struggle with rectifying the issue fast enough (high Mean Time to Repair).
Achieving high QoE goals with a limited budget
As if the aforementioned problems aren’t enough, they are further complicated by the fact that operations teams need to achieve very high QoE with limited budgets. Ultimately, that’s what it truly comes down to in live stream monitoring: to not only monitor issues, but to resolve them as fast as possible in a resource-efficient manner and, ideally, before they can even affect the viewer.
NOC challenges resulting from remote live stream monitoring
Telecommuting or remote work is not a new trend for tech teams, but it has been significantly accelerated by shelter-in-place regulations in recent times. This poses yet another challenge for streaming operators: “How do we monitor everything if we can’t be in the same room?”

Under normal circumstances, network engineers in streaming operations work side-by-side in a physical room with more than a dozen screens displaying details about system and server health, streaming content, and network. Phone lines wait tensely for customers to ring with delivery problems. All in all, it’s a collaborative environment where everyone works together to triage issues and ensure the best possible viewing experience – and therein lies the problem.
“The NOC challenge with connecting through a VPN isn’t only the availability of the connection itself, it’s also replicating the “wall of screens” within the room.“
Many of the systems and servers involved in the streaming workflow (content origin, caches, encoders, transcoders, packagers, and all the in-between network gear) might only be reachable from within the corporate network, or the physical room. Of course, many businesses have provisions for outside workers to access network resources. The NOC challenge with connecting through a VPN isn’t only the availability of the connection itself. More importantly, it’s replicating the “wall of screens” within the room.
The reason for this is that part of live stream monitoring isn’t just seeing the data flowing across the screens, it’s seeing the monitor for one system right next to another; it’s seeing all the data at once. A network engineer working from home, even with three screens, still has to toggle between systems, and while toggling to one, they might miss something critical on another.
Operations teams must now find ways of effectively replicating that collaborative process in a remote environment when employees access data from different locations and devices.
Live stream monitoring solutions
It’s clear that operations teams face major live stream monitoring challenges. They must ensure high QoE at all times whilst managing data fragmentations, evolving tech stacks, and limited budgets. On top of that, they need to do this in an environment that supports telecommuting. The following sections look at different live stream monitoring solutions for operations teams to overcome these obstacles. These include building and implementing a monitoring strategy, using the cloud to allow remote monitoring, and introducing a monitoring harness.

Defining your live stream monitoring strategy
Remote network monitoring is a serious business consideration. Much like disaster recovery and business continuity planning, enabling hardware and software behind the corporate firewall to be monitored remotely is not something you can just decide on overnight. Instead, it requires a lot of thought and a well-defined strategy. Here’s how to develop a proper remote monitoring strategy.
1. Listen to your operations team
The first step is to listen to the people who monitor network equipment in the NOC. What do they need to monitor remotely? What makes sense? What kind of data do they need to see and how frequently? Answering these and other questions will help direct decisions into how to enable remote monitoring.
One of the most critical questions to answer is, “What needs to be monitored?”. Although it’s easy to enable everything, that overwhelms the people who need to make decisions based on the data. All the widgets and graphs in the world won’t help you make sense of things. Keep your network engineers and operations folks focused on what needs to be monitored, not what can be monitored.
2. Determine who needs access
The second step is to determine who needs to see what data. While it is significantly influenced by step 1, this is about the organisation of the monitoring requirements communication by network engineers into policies. It doesn’t make sense to enable monitoring from every network component for every network engineer, as that can quickly devolve into a security issue. You need to clearly define roles, assign those roles to engineers, and group network equipment or services underneath each role.
3. Set KPIs
Once you’ve gone through understanding the critical elements to monitor and who should have access to seeing that data remotely, you need to establish how to be actionable from the data. Set thresholds. Determine measurements. Create boundaries around your data that relate to your business goals.
Above all else, keep-it-simple-stupid (KISS). Think of a traffic light – monitoring data from network systems should be as simple as green equals everything is working fine (within the established KPI) and red equals an error (deviation from KPI).
4. Decide how you’ll collect and store data
Once you’ve established your monitoring strategy, there are some logistical concerns such as where you’re going to store the data. Although many network services, including hardware, are much smarter now and capable of throwing off lots of operational bits and bytes, you need a way to collect it in an organised manner.
There are numerous log analysis tools, such as Splunk and New Relic, that can collect data from various network components. Interfacing through APIs, these services can combine hardware data, software data, and even cloud-based services data into a single data pool. This is a great way to bring everything together. Of course, there’s not much actionable insight from such a large data pool, but at least it’s in one place. Given that many of those tools, like Splunk, can be accessed remotely, it provides a tangible way for operations engineers to get to the data they need.
5. Ensure proper data processing and visualisation
Monitoring doesn’t end with collection and storage. Part of the monitoring strategy must take into account several critical steps beyond just collecting and storing the data. Most notably, these are normalising and visualising data as well as making it accessible to the right people in the right format and place.
Normalisation - With collected data stored in a relational database, it’s critical to normalise it. In many cases, the data may not be particularly useful in raw format, especially when it needs to be correlated. It’s also possible that different systems performing similar functions are reporting data in different ways. Regardless, you must implement rules and policies for how data is to be transformed after storage. This transformation will ultimately make it more useful when visualised.
Correlation and visualisation - One of the key steps in making network monitoring data actionable and meaningful is to correlate it. How is the data collected from one system impacted by other systems’ upstream? Correlating data, to identify the relationships between different network components, enables decision making. Identifying the patterns and seeing the connections is a massive step in ensuring network operations personnel can do their job.
But data correlation doesn’t mean much if it’s still just a bunch of numbers. Visualisation makes sense of those correlations, especially when that visualisation is built on a foundation of KISS. It should tell a clear story so that when someone looks at it, they can say, “yep, I see where there’s a problem.” If you force network operations to waste too much time trying to figure out where the problem is within the visualisation, that’s valuable time that could be focused on solving a problem.
Accessibility - Now you have data being collected, access policies enabled, and correlation and visualisation producing a simple view, but that isn’t any good if it’s not available remotely. Whatever tool you decide upon for visualisation, it needs to be accessible from the outside. That means that it needs access to the datastore into which all the monitoring data is being collected. In addition to being accessible, that monitoring solution should be responsive. Yes, most people are currently working from home, but you aren’t creating and enacting your remote monitoring strategy for today, you are doing it for tomorrow. You need to empower your remote network engineers and operations personnel with tools that work on the devices they have at their fingertips – like their mobile phones.
6. General consideration: keep security top-of-mind
As you are building out your strategy and setting access policies, you also need to think about how data can be collected from behind the firewall and stored outside it. Keeping your monitoring secure, when it’s not hidden within a NOC deep in the building, is critical and involves a host of considerations including user authentication (even if employing a VPN), data encryption (especially if using the cloud), and more. Collecting data from remote systems, often not exposed to the internet, may require APIs and other middleware that are, again, security concerns. The simple fact is that embracing the concept of monitoring network resources remotely–such as those in video streaming that would not normally be available outside the corporate firewall–requires an approach that identifies the needs of network engineers used to the NOC balanced against corporate IT policies and overall security.
Implementing your live stream monitoring strategy
Committing your strategy to paper, or the whiteboard, is one thing, but a strategy won’t do you any good unless you can implement it effectively and efficiently. Below are six phases of implementation you can follow for a clear path from strategy to action.

1. Ensure you can see the big picture
Many of the problems that crop up in implementing a strategy often result from a simple adage: not being able to see the wood for the trees. It’s easy to get caught up in the details, such as which element is being monitored and who has access, but focusing solely on each tree may be too myopic. You need to see the entire monitoring approach/strategy and its implementation from a high-level view.
2. Map relationships and workflows
Once you have that 30,000-foot perspective, you need to understand how everything fits together. This phase is directly related to correlating data. You need to see how data flows through your entire workflow, through every piece you have selected for monitoring. This way, you’ll have a clear picture of the flow of potential errors when correlating and visualising the data.
3. Select best-of-breed monitoring solutions
When businesses are reactive, like what streaming platforms needed to do to keep monitoring their workflow when network operations personnel were working from home, the tendency is to implement something that “just works.” However, that solution won’t be the best in the long term as telecommuting continues to rise. What’s worse is that without proper planning now, there won’t be time to do a proper bakeoff or PoC later. It’s crucial to take the necessary time as soon as possible to assess the options and select the appropriate monitoring solution for each component that needs to be watched.
As you evaluate different monitoring solutions, you will need to address a fundamental question: “Should I utilise hardware monitors or software monitors?”. In Touchstream’s experience, software-based monitoring has several significant advantages over hardware monitors:
- Deployment on existing infrastructure. Software monitors, unlike hardware, are easily deployed on already existing infrastructure, such as a web server. This makes deployment and management easier as network engineers with remote access to the physical network, such as via VPN, can install or update the monitors on whatever boxes they have available that are already connected.
- Reduced maintenance. Overall maintenance is significantly reduced. The monitoring software packages can be managed via CI/CD pipelines, enabling monitoring, as a function, to become a component of DevOps rather than just traditional network engineering. If a hardware monitor fails, remote hands must address the issue. This is complicated if access to the physical location where they are installed is limited or not allowed at all.
- Remote services. The most significant advantage a software-based approach has over a hardware-based one is the ability to monitor remote services. Software monitors deployed in cloud-based instances can collect data from third-party SaaS services which are involved in the streaming workflow by acting as pass-through agents. Some traffic from a remote service operator, such as a CDN, can pass through the agent, providing insight into an otherwise black-box system.
4. Implement in bite-sized chunks
Remotely monitoring an entire streaming workflow, which may include hardware and software behind the firewall as well as cloud-based services, is a complicated endeavour to do correctly. Yes, you can grab data from workflow components and people can muddle through it, eventually figuring out how to relate it to other components. However, that is not a long-term tenable solution. With time on your side to strategise and implement slowly and diligently, it behoves you to do so in stages. Don’t try to tackle everything at once. Be agile and address each component in your big picture as an individual project. You may find that a best-of-breed monitoring solution targeted at one component also works for another, but don’t go into the implementation of your remote monitoring strategy with that in mind.
5. Bring it all together
Although you will have spent time creating your strategy and implementing it piece-by-piece, you will need a more holistic approach to visualisation. You can’t have multiple monitoring tools each requiring their own dashboard. That defeats the purpose of remote monitoring in which operations personnel aren’t in front of dozens of screens to see everything at once. Whatever visualisation tool you decide upon, it will require you to strategise about it first: what needs to be displayed, how relationships between data sources are accounted for, and, of course, KISS. Visualisation is really where the rubber meets the road. However you articulate the presentation of all the monitoring data, it has to be done in such a way that makes it simple and easy to identify root causes and troubleshoot issues down to the streaming workflow component and user session.
6. Embrace continuous improvement
Cutting across your strategy and implementation has one overriding principle: remote monitoring is not a one-and-done activity. Just because you strategise, select which systems need to be monitored remotely, build policies, implement, and visualise, that doesn’t mean you're finished. There are always elements of that strategy or implementation to improve, as well as new monitoring technologies and visualisation approaches to consider. Embracing continuous improvement for your remote monitoring strategy, whether reactively or proactively, will pay off in the long run by ensuring your operations personnel and network engineers have the tools they need to shorten troubleshooting time and root cause analysis. Both of which significantly impact viewer satisfaction and subscriber health.
Enabling live stream monitoring in remote environments via the cloud
Monitoring single, discrete systems in a streaming workflow isn’t the most efficient method of tracking issues. In fact, it’s pretty daunting to piece together the root cause from data collected across multiple systems. The NOC team is responsible for detecting problems, and any speed and efficiency they could gain by making root cause analysis easier and faster only benefits the business by preventing technical errors before viewers cancel their subscription.
To develop a solution for remote network operations, the data from the systems has to be available outside of the corporate network. The best way to accomplish this is through the cloud. By enabling each component of the workflow–whether physical or software–to beacon data to the cloud, the fundamental issue of data accessibility has been addressed. Security must be a priority, but once the data and access to it are protected, the first major hurdle has been tackled. Now that there’s a steady stream of data from streaming components both inside and outside the network, cloud-based software and processes can act against it. The data can be sorted, collated, aggregated, and compared. Intelligent systems can be used to identify patterns or relationships, which is something that would have had to have been done visually in the physical room with all the screens.
Imagine it… a NOC in your pocket
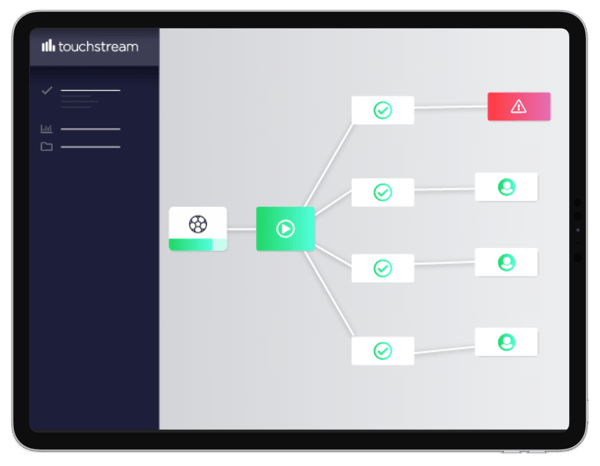
When the data is in the cloud, the ideal solution would be to visualise it within a browser window. If it was browser-based, data could be accessed from the comfort of the couch, the passenger seat of a car, or even the beach. However, just displaying data in the browser isn’t that exciting; it still requires visual acuity to find the pattern. What if the data was pieced together along a timeline so that a single viewing session (where an error had occurred) could be traced back to the origin? It would be like a DVR for network operations. This is exactly what a powerful monitoring harness does, as the next section will show.
Live stream monitoring harness
Setting up a monitoring harness is key for creating broadcast-like Quality of Service (QoS) for streaming. As such, it should be at the heart of your live stream monitoring strategy and implementation. This harness is like the coat rack for your monitoring tools. Think of it as the evolution of the quality-of-service system used to support traditional broadcast, but rather than a monolithic system tied to specific hardware, it’s flexible and adaptable to the mutable world of streaming technologies.
What is a monitoring harness exactly?
A monitoring harness is just that: a framework into which other, complementary components can be plugged for enhanced functionality. We’ve all seen the harness in front of a wagon. Regardless of the number of horses hitched to it, the harness supports more than just one horse. So when more pulling power is needed, more horses are yoked to the harness.
Your monitoring harness works in much the same way. As a framework for capturing and visualising streaming data, it’s based on a simple principle: enable easy connectivity to stream video technologies within the stack. The harness itself serves two basic purposes: to gather data from components that are yoked to it and to provide connection points via APIs.
A harness is a timeless and effective monitoring solution
One of the biggest issues with streaming technologies is they are constantly evolving. Yes, there are some fundamental components, like segmented HTTP delivery, which are here to stay, but the way they are implemented is still up in the air (CMAF vs HLS vs DASH , etc.). A monitoring harness based on API connectivity, data aggregation, and normalisation isn’t employing any technologies or strategies that are going to change. As a result, the harness itself won’t ever need to be replaced.
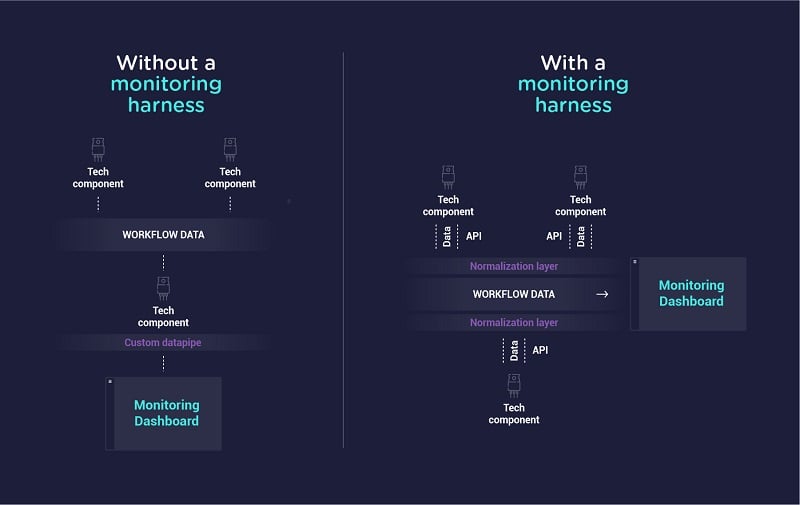
The image above shows the main benefit of implementing a monitoring harness. As you replace or upgrade components within the video streaming technology stack, these new components can be easily plugged into the harness via API to enable gathering and visualisation of the streaming data. What’s more, engineers don’t need to be continually re-trained because the core functionality of the harness–data gathering and visualisation–doesn’t change. Instead, they can be trained just once on how to read and interact with the monitoring harness dashboard and are then set up for good.
👉 You may like: Monitoring harness white paper
Live stream monitoring example: Seven West Media

To illustrate an example of a comprehensive OTT live stream monitoring infrastructure, let’s review the set-up of a leading broadcaster: Seven West Media. As one of Australia’s biggest integrated media companies, they cover large international sporting events and reach up to 300,000 concurrent viewers on their OTT streaming platform. It’s therefore vital they provide a robust system that mitigates any potential errors.
To cover all bases, they use a comprehensive monitoring infrastructure to ensure high QoS for live streams. This includes solutions along the entire video delivery chain:
- MUX for client-side analytics
- Touchstream for CDN insight and content availability monitoring
- Amazon AWS for platform-as-a-service functionality
- AWS Elemental for live encoding on-premises
- Akamai and Amazon CloudFront for delivery
- Brightcove for VoD asset management and playback
- Google DFP and Yospace for live ad-insertion
Looking at live stream monitoring, in particular, Seven West Media leverages a combination of solutions for their active and in-player monitoring. In-player monitoring, as provided by MUX, allows the broadcaster to get real-time feedback while their end-user is viewing their content. Active synthetic monitoring, such as that provided by Touchstream’s StreamCAM (which now evolved into Touchstream VirtualNOC), meanwhile, runs a constant playback test by simulating the viewing experience in a specific location online. A combination of both these approaches provides the most robust monitoring possible.
Using this wide array of solutions and making them work together, Seven West Media ensures they provide the QoS consumers expect from such a prominent broadcaster.
“Data is critical for us to optimise quality-of-service across the entire OTT workflow. We can capture and analyse an incredible level of detail, with clear dashboards that allow everyone in the team to efficiently troubleshoot issues. Touchstream’s StreamCAM solution provides us with key data we need about CDN performance so that we get a complete end-to-end picture of our linear stream delivery.”
- Damian McNamara, Head of Cloud Video at Seven West Media
👉 To read the full case study, click here.
Live stream monitoring benefits
With proper live stream monitoring strategy, solutions, and monitoring harness in place, broadcasters unlock a wide range of benefits.
Improved service quality
Effective live stream monitoring significantly boosts Quality of Service by helping broadcasters provide round-the-clock uptime as well as deliver a low probability of downtime, low error rates, high bandwidth, and superior latency. Besides content and price, QoS is the key differentiator driving success for streaming broadcasts as viewers expect TV quality in OTT live streaming, regardless of the platform or device they choose. As such, broadcasters that implement a comprehensive monitoring strategy gain a major competitive advantage.
Reduced incident volume
Having a robust system enables broadcasters to minimise the types of incidents that lead to user churn to an almost inconsequential level. This is done largely by detecting problems before they even happen. The streaming pipeline is complex, so having an integrated system that traces errors from glass to glass and displays them in one simple single-view dashboard means that issues are far more preventable. Touchstream’s active monitoring, for example, runs tests on every bitrate of every channel and format. All these are monitored from high-quality PoPs located in the cloud on diverse transit networks and are viewable through the VirtualNOC dashboard. Problems that may arise in the delivery workflow are visualised, meaning they can be dealt with before they impact viewers.
Decreased cost of customer complaints
When it comes to errors and issues in live streaming OTT, there is a huge cost to being reactive, rather than proactive. The first is simply user churn. Demand for broadcast-quality OTT streaming means competition is sky-high. Imagine a live streaming event being watched by hundreds of thousands of users on one platform. Due to a preventable error, a decisive moment suddenly isn’t visible because their stream starts buffering, stalls or it fails to play.
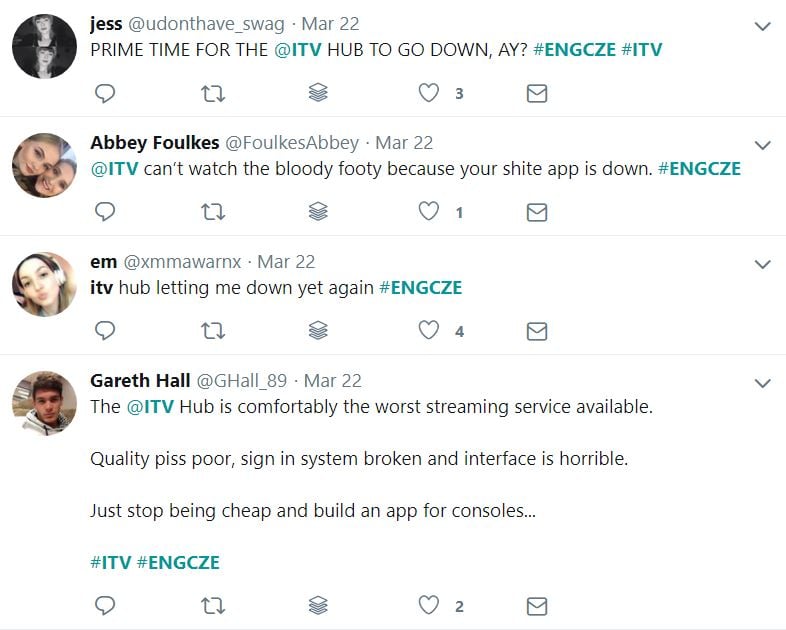
England fans fume on social media as ITV hub goes down during a live stream of Czech Republic game. The story was even covered by a major newspaper.
Today, user feedback is instant and vocal on social media, so an error like this can quickly turn into a PR disaster. This triggers a chain reaction: users churn to alternative platforms and social media backlash deters potential new customers from signing up or trying that broadcaster. What’s more, even if users don’t leave your platform, the cost of user phone complaints adds up rapidly to adversely affect your profit margins. Forrester, for example, estimates a serious QoE issue during a major sporting event could cost $1.2 million in call centre expenditure if 100,000 users call in to complain. Clearly, these cumulative consequences result in a serious downturn in revenue. Thanks to live stream monitoring, all these expenses and damages are limited.
Faster resolution of outages
When outages do happen, a comprehensive live stream monitoring infrastructure facilitates better problem management. In-player monitoring can detect when an issue is negatively affecting end-users, and exactly how many of them are being affected. When coupled with the high visibility of an integrated single-view dashboard covering the entire pipeline, from origin to delivery to content delivery network, this allows operators to determine the fastest possible solution.
Higher productivity for the business and IT
A seamless CDN with high visibility that displays the entire delivery workflow facilitates the rapid identification of issues, as soon as they appear. This means the broadcaster can reallocate the time and resources previously spent on reactively fixing incidents to other business areas, such as engineering.
Live stream monitoring means a competitive edge in the market
OTT live streaming is growing continually to become an ever-more competitive market, with more consumers turning to OTT as an alternative to TV. As OTT becomes more developed and more ubiquitous in broadcasting, companies providing an error-free streaming service will distinguish themselves as a serious player and achieve sustainable, long-term growth. To attain this, they need a comprehensive live stream monitoring strategy and toolset to equip them with the capabilities necessary to provide the highest possible quality service.
Are you looking for more tips to improve your live streaming? Download our ebook here.

