
Cloud monitoring for your streaming video components is already complicated. With multiple cloud vendors, like CDNs, combined with containers and instances, it can be difficult to capture the data needed to ensure the best viewer experience. This gets even more complex with serverless functions.
This evolution of the video tech stack isn’t easily monitored–which is why you have to think about data collection at every step of the engineering process. Thankfully, there are techniques to improve your observability and fold in your serverless functions to your overall cloud monitoring strategy.
Serverless functions and the video streaming tech stack
As an aspect of modern application development, many streaming operators are moving towards streaming microservices. Of course, this helps tremendously in both development and application reliability. When components within the stack are loosely coupled, failure of a single element doesn’t take down the entire streaming workflow. Streamlining operations can ensure the service remains operational by isolating elements in this fashion. What’s more, it’s much easier to make microservices redundant and deploy them using containers.
However, microservices, and the containers in which they run, can still be inefficient. They rely on dedicated instances within the cloud which, in some cases, may require reservations and other planning to ensure available capacity. Serverless functions, on the other hand, don’t. They exist within serverless infrastructure, which is capacity spread across cloud instances. What’s important here is that the streaming operator is no longer responsible for managing the instances and the capacity. This means that the serverless functions can leverage whatever capacity is needed. Much like how elastic infrastructure is spun up and spun down depending upon need, serverless functions only operate when required. They scale up within the compute environment provided by a serverless cloud provider as demand necessitates (although “scaling” for serverless functions refers to the amount of resources needed, like CPU cores and memory, rather than entire virtual instances).
The challenges of monitoring serverless functions
Even as the video streaming tech stack moves towards serverless functions, the serverless environment is heading further towards the edge. This provides an added benefit: those functions can operate much closer to the end-user, improving performance metrics for key workflow components. However, serverless functions are harder to monitor. This makes troubleshooting difficult within end-to-end cloud monitoring systems that don’t account for their unique complexity.
To understand the challenges of monitoring serverless functions in more detail, here’s an example of manifest manipulation, which is often accomplished at the edge:
- The user makes an action in the video player that triggers the function, which will modify the manifest for that user’s session. This might be watching an ad all the way through rather than skipping it
- The function manipulates the manifest according to its business logic. Perhaps this is stitching in future ads which are reflective of the viewer’s behaviour of not skipping the ad
- Once accomplished, the function is destroyed and the new manifest is pushed down to the player
The benefits of offloading capacity management for the streaming video tech stack to a serverless infrastructure provider, as well as the stateless and ephemeral nature of serverless functions, are balanced by the challenges of monitoring a serverless function like that performing manifest manipulation. For example, when the function is instantiated, accomplishes its task, and is destroyed in just a matter of seconds, how can ongoing data be gathered?
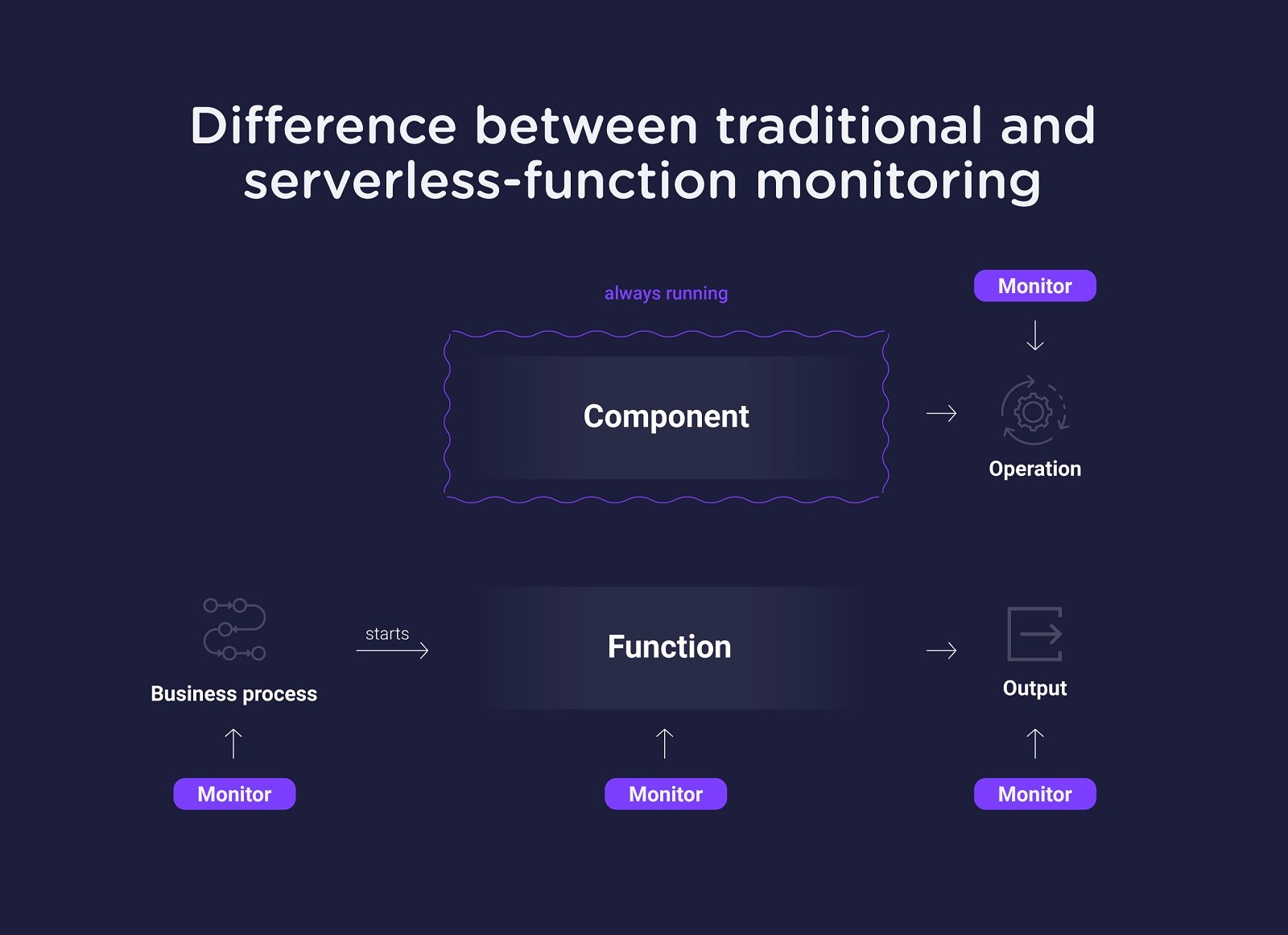
The key to plugging serverless functions into your cloud monitoring approach isn’t just to capture what’s happening with the function itself. It’s to monitor everything related to it as well: the business logic that triggers it as well as the output. In our example of manifest manipulation, if the function was triggered and executed correctly, but the result was bad (i.e., an error in the manipulation that results in a corrupted manifest, or the wrong ad is inserted into the manifest), then although the function operated properly, it failed.
How to achieve end-to-end cloud monitoring
Although there are challenges to including serverless functions in your cloud monitoring, there are several things you can do to ensure you have visibility on these little bits of code:
- Build your functions to monitor. To do this, you’ll need to ensure that all of your serverless functions have proper garbage collection and logging. This will allow operations to understand what happens when the function is instantiated, takes action, and is destroyed
- Monitor before, during, and after. Just gathering data about a function’s operation isn’t enough to help root cause analysis. You need to test the output. That means you’ll need to build additional functions to test. Of course, these may not need to be real-time, depending upon when the output of a serverless function is needed (the next ad played, for example, might not be for 10 minutes)
- Connect everything to your cloud monitoring harness. By connecting the data from before the serverless function (i.e., the business triggers), the actual serverless function (i.e., did it turn up correctly, run properly, and then disappear), and the output, you’ll have an end-to-end view of everything involved. This will result in quicker MTTR
Just like any component within the workflow, operational considerations must be made for serverless functions. Suppose root-cause analysis is hampered by a lack of data or visibility into the functions. In that case, although those functions may be more efficient for the overall workflow, they may actually hurt the ability of operations to figure out and solve issues. The efficiency of a streaming video stack is both a combination of the way the components are coded (i.e., monolithic versus microservices versus serverless functions) and how quickly data can be surfaced for operational analysis and resolution.
Go serverless but without sacrificing operational insight
It seems like an evolutionary trend within streaming platforms to move from monolithic development to microservices and finally to serverless functions. However, even though doing so may make your technology stack more efficient, resilient, and reliable, it can present new challenges to live stream monitoring which could undermine the efficiency of your operations. To ensure that you can connect those serverless functions into your end-to-end cloud monitoring strategy, you’ll need to make monitoring considerations part of the decision-making process. Don’t just build your functions and then figure out how to monitor them. Make decisions about data collection at each step of the development process to capture what happens before, during, and after the functions run their course.
To find out how Touchstream can help you get the most out of your serverless functions without sacrificing the operational insight you need to ensure the best possible viewer experience, request a demo now.
